Python 爬虫:requests + BeautifulSoup4 爬取 CSDN 个人博客主页信息

Python 爬虫:requests + BeautifulSoup4 爬取 CSDN 个人博客主页信息(博主信息、文章标题、文章链接) 爬取博主每篇文章的信息(访问、收藏) 合法刷访问量?
Published on April 30, 2020 by WULH
Python 爬虫 BeautifulSoup4
12 min READ
Python 爬虫:requests + BeautifulSoup4 爬取 CSDN 个人博客主页信息(博主信息、文章标题、文章链接) 爬取博主每篇文章的信息(访问、收藏) 合法刷访问量?
Python 爬虫:requests + BeautifulSoup4 爬取 CSDN 个人博客主页信息(博主信息、文章标题、文章链接) 爬取博主每篇文章的信息(访问、收藏) 合法刷访问量?
关于 BeautifulSoup4
BeautifulSoup4 是爬虫必学的技能。BeautifulSoup 最主要的功能是从网页抓取数据,BeautifulSoup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python 默认的解析器,lxml 解析器更加强大,速度更快,推荐使用 lxml 解析器。
Beautiful Soup官网:https://www.crummy.com/software/BeautifulSoup/
Python 安装
网络上有很多优质的安装教程。
requests 安装
最简单的方法:打开命令行,输入命令:**pip install requests **
BeautifulSoup4 安装
可以访问官网 https://www.crummy.com/software/BeautifulSoup/ 查看安装方式。
最简单的方法:打开命令行,输入命令:pip install beautifulsoup4
或者是输入命令:pip3 install beautifulsoup4
等待它安装完成,你就成功安装 BeautifulSoup4 了。
lxml 解析器安装
最简单的方法:打开命令行,输入命令:**pip install lxml **
如果安装过程中出现其他问题或异常请自行百度,这不是本文章的重点。
关于 CSDN 个人博客主页
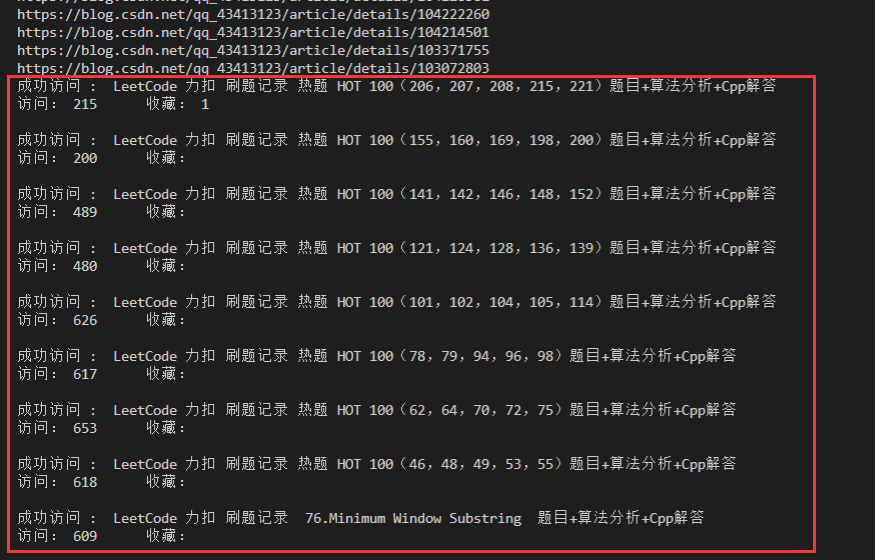
我们打开一个 CSDN 个人博客主页,以我自己的博客主页为例子,如下图所示:
可以看到我用红色框框起来的地方就是这个 CSDN 个人博客主页的链接 url,用于访问指定的网页使用。
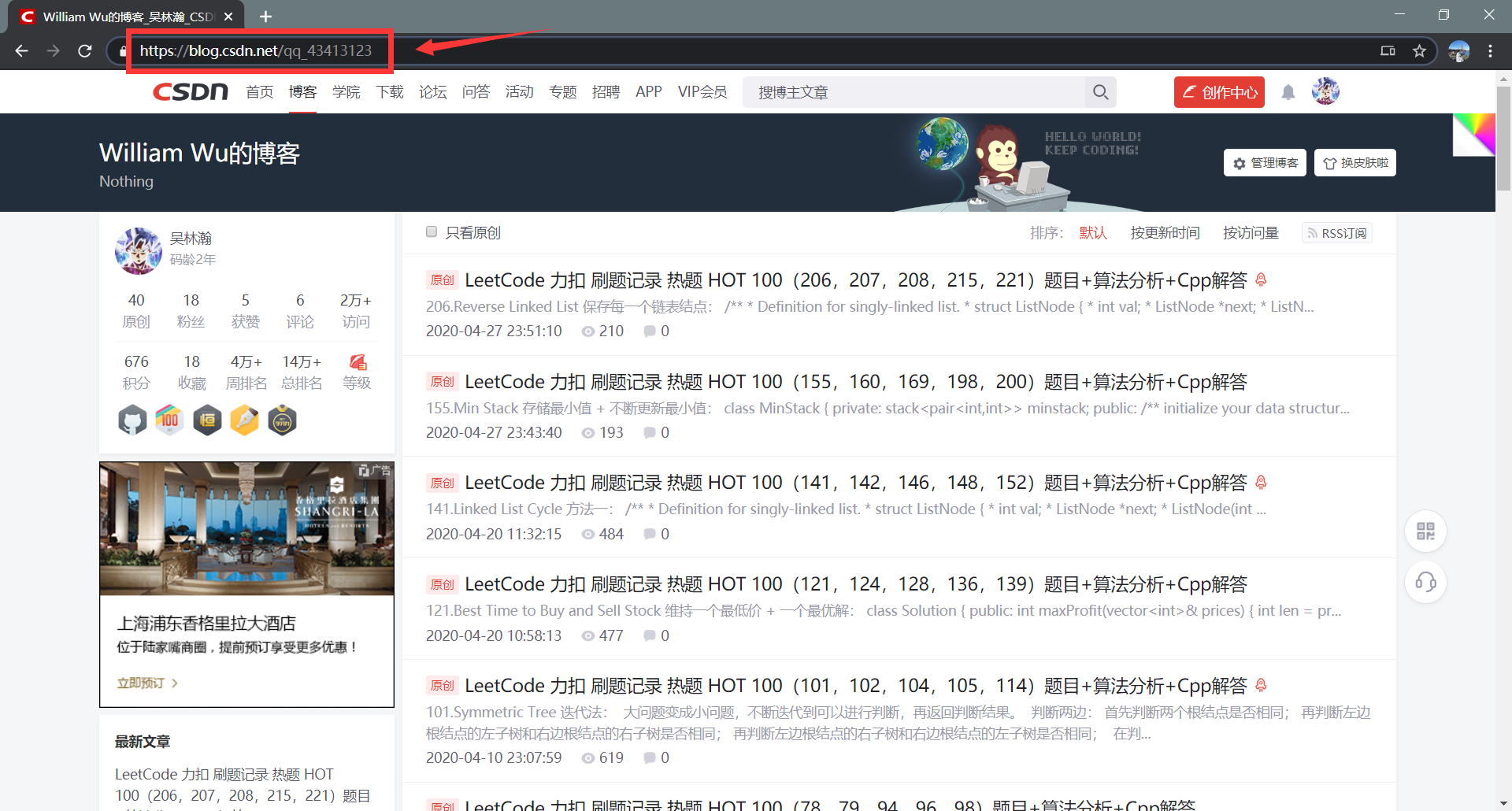
查看这个网页的网页内容(HTML),可以通过按下键盘的 F12 查看,如下图所示:
我用红色框框出来的部分就是我们这篇文章的重点,就是我们要爬取出来的信息。
我们需要通过在网页的HTML中进行层层定位,找到包含我们需要的信息的块,再从块中提取出信息。
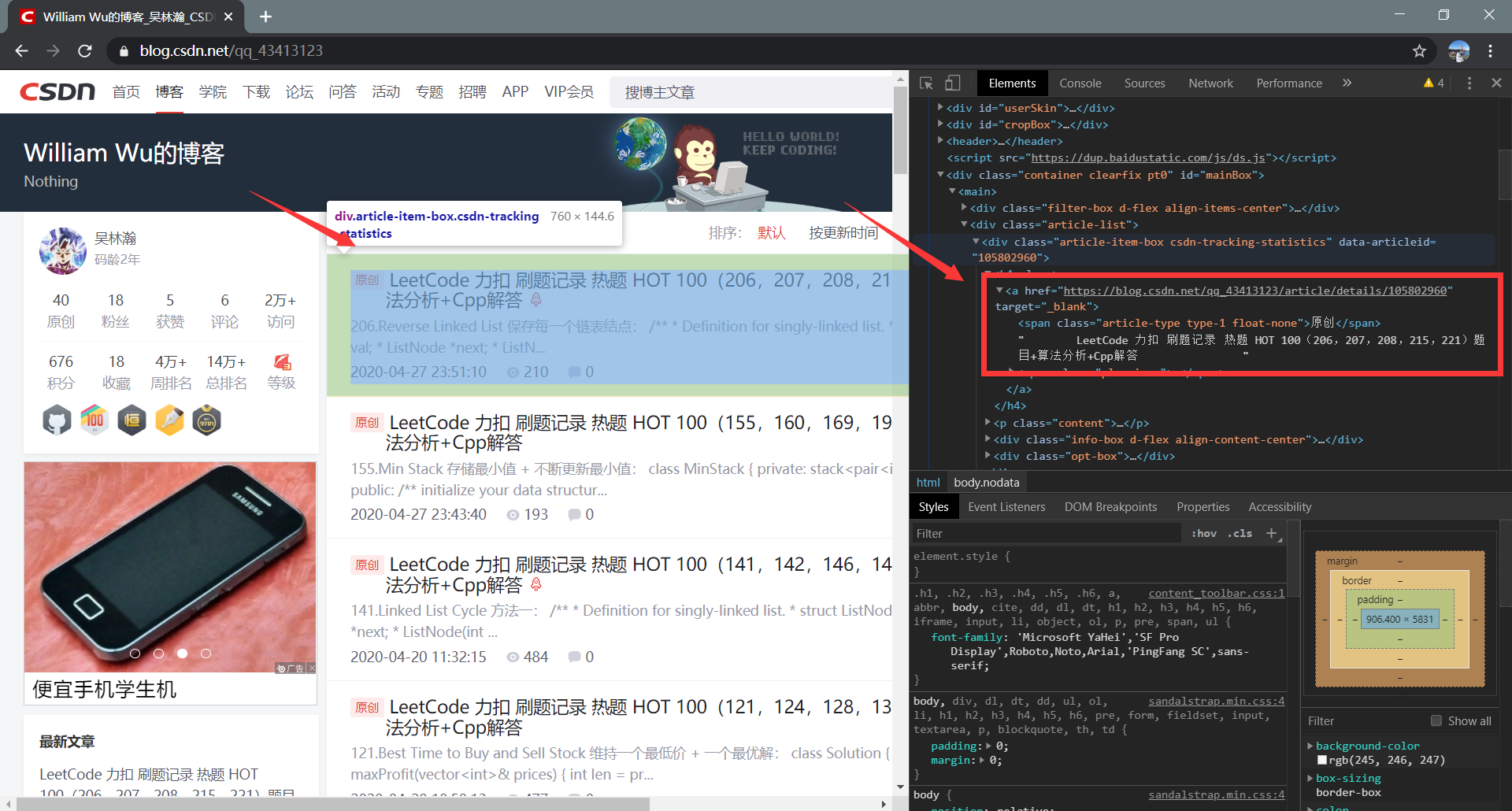
Python 爬虫实战
导入模块
导入 BeautifulSoup4 模块:from bs4 import BeautifulSoup
导入 requests 模块:import requests
其中一些模块的导入我在后文中会解释。
# 处理网页内容
from bs4 import BeautifulSoup
# 处理 url 资源
import requests
# 用于随机处理
import random
# 时间使用
import time
# 正则表达式使用
import re
构造 user_agent 库
user_agent库:每次执行一次访问随机选取一个 user_agent,防止过于频繁访问被禁止
# user_agent库:每次执行一次访问随机选取一个 user_agent,防止过于频繁访问被禁止
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
请求网页并获取网页内容
输入 url,请求网页并且输出网页信息。
首先,使用 random.choice (所以需要导入 random 模块)从 user_agent 库中随机取出 user_agent 构建请求头。然后调用 requests.get() 方法请求网页,使用 raise_for_status() 方法判断是否出现异常。最后,调用 BeautifulSoup() 使用 lxml 解析器获取网页内容。
详细请看我的代码和相关注释。
# 输入 url,请求网页并且输出网页信息
def get_response(url):
# random.choice 从 user_agent 库中随机取出 user_agent 构建请求头
headers = {
'user-agent':random.choice(USER_AGENT_LIST)
}
# GET
resp = requests.get(url,headers=headers)
# 判断是否出现异常
resp.raise_for_status()
# 使用 lxml 解析器
soup = BeautifulSoup(resp.content, 'lxml')
return soup
爬取文章标题和文章链接
首先,使用 get_response() (详见上一步)获取博客主页的网页内容。
接下来就是层层定位了。我们将会频繁使用 find() 和 find_all() (具体用法可以上官网查阅或者看我代码)。
先是提取出网页中的文章列表内容,然后在文章列表内容中提取出所有文章的信息。
接下来就是从每一条文章信息里面提取出文章的标题和链接信息。
此时需要建立文章链接的集合:urls,将每一篇文章的链接 url 加入文章链接集合中。
最后函数返回文章链接的集合 urls。
详细请看我的代码和相关注释。
# 爬取个人博客主页中博主的文章标题和文章链接
def get_url():
# 获取博客主页的网页内容
soup = get_response(my_website)
# 提取出网页中的文章列表内容
#class="article-list"
article_div = soup.find('div', attrs={'class': 'article-list'})
# 提取出所有文章的信息
articles_titles = article_div.find_all('h4')
# 从每一条文章信息里面提取出文章的标题和链接信息
articles = []
for article_title in articles_titles:
articles.append(article_title.find('a'))
# 建立文章链接的集合,输出文章的标题和链接
# 将每一篇文章的链接 url 加入文章链接集合中
urls = []
for article_url in articles:
print(article_url.text.strip())
urls.append(article_url.get("href"))
print('URL : ', article_url.get("href"), end = '\n\n')
#返回文章链接的集合
return urls
爬取关于博主的个人信息
首先,使用 get_response() (详见上面)获取博客主页的网页内容。
接下来就是层层定位了。我们将会频繁使用 find() 和 find_all() (具体用法可以上官网查阅或者看我代码)。
先从网页内容中提取博主的个人简介信息,然后提取关于(原创,粉丝…)的信息。
接下来就是输出我们提取到的信息。
详细请看我的代码和相关注释。
# 爬取个人博客主页中关于博主的个人信息
def get_Profile():
# 获取博客主页的网页内容
soup = get_response(my_website)
# 从网页内容中提取博主的个人简介信息
#id="asideProfile"
Profile = soup.find('div', attrs={'id': 'asideProfile'})
# 提取关于(原创,粉丝...)的信息
#class="data-info d-flex item-tiling"
item_tiling = Profile.find('div', attrs={'class': 'data-info d-flex item-tiling'})
# print(type(item_tiling))
# 输出提取到的博主个人信息
information = item_tiling.find_all('dl')
for inf in information:
# print(type(inf.text))
classification = inf.find('dd')
print(classification.text, end = " : ")
print(inf.get('title'))
访问每一篇文章并获取文章的信息
首先,使用 get_response() (详见上面)获取文章的网页内容。
接下来就是层层定位了。我们将会频繁使用 find() 和 find_all() (具体用法可以上官网查阅或者看我代码)。
先提取文章的标题栏,得到文章的标题,并且输出。
接下来是提取文章的各种信息,提取文章的访问数,并且输出。
提取文章的收藏数目,此时需要使用正则表达式匹配收藏数的数值(所以需要导入 re 模块),并且输出。
详细请看我的代码和相关注释。
# 访问每一篇文章,获取文章的信息
def get_visit(url):
# 获取文章的网页内容
soup = get_response(url)
# 提取文章的标题栏,得到文章的标题
#class="article-title-box"
article_title_box = soup.find('div', attrs={'class': 'article-title-box'})
print('成功访问 : ', article_title_box.text.strip())
# 提取文章的各种信息
#class="article-bar-top"
article_bar_top = soup.find('div', attrs={'class': 'article-bar-top'})
# 提取文章的访问数
# class="read-count"
read_count = article_bar_top.find('span', attrs={'class': 'read-count'})
print('访问:', read_count.text.strip(), end = '\t')
# 提取文章的收藏数目
# id="blog_detail_zk_collection"
collection = article_bar_top.find('a', attrs={'id': 'blog_detail_zk_collection'})
# class="get-collection"
collection_num = collection.find('span', attrs={'class': 'get-collection'})
# 使用正则表达式匹配收藏数的数值
number = re.sub('\D', '', collection_num.text)
print('收藏:', number, end='\n\n')
主函数执行爬虫
首先需要定义文章链接的集合:all_urls,用于保存文章链接。
接下来使用 get_Profile() (详见上面)爬取个人博客主页中关于博主的个人信息。
然后使用 get_url() (详见上面)爬取个人博客主页中所有文章的信息,得到每篇文章的链接 url。
将得到的文章链接保存在 all_urls 中,此时可以查看爬取得到的文章链接 url。
接下来是关键的一步:访问每一篇文章,获取文章的信息(合法刷访问量)
我们从文章链接集合中取出一条文章链接 url,然后使用 try 和 get_visit(url)(详见上面)来访问这篇文章。
访问结束之后可以查看此时的博主个人博客信息,使用 get_Profile()(详见上面)。
此时还需要等待一段时间,否则不会增加访问量。
调用 sleep() (所以需要导入 time 模块)进行等待。
详细请看我的代码和相关注释。
# main
if __name__ == '__main__':
# 文章链接的集合
all_urls = []
# 爬取个人博客主页中关于博主的个人信息
get_Profile()
# 爬取个人博客主页中所有文章的信息,得到每篇文章的链接 url
all_urls = get_url()
print('获取到的链接数:',len(all_urls))
# 查看爬取得到的文章链接 url
for url in all_urls:
print(url)
# 访问每一篇文章,获取文章的信息(合法刷访问量)
for loop in range(30):
# 从文章链接集合中取出一条文章链接 url
for url in all_urls:
try:
# 访问这篇文章
get_visit(url)
except Exception as e:
print(e)
continue
# 查看此时的博主个人博客信息
get_Profile()
# 等待一段时间
sleep_time = random.randint(65, 80)
print('等待', sleep_time, 's')
time.sleep(sleep_time)
Python 爬虫完整代码
# 处理网页内容
from bs4 import BeautifulSoup
# 处理 url 资源
import requests
# 用于随机处理
import random
# 时间使用
import time
# 正则表达式使用
import re
# user_agent库:每次执行一次访问随机选取一个 user_agent,防止过于频繁访问被禁止
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 这是本人的 CSDN 个人博客主页,可以改成其他博主的
my_website = 'https://blog.csdn.net/qq_43413123'
# 输入 url,请求网页并且输出网页信息
def get_response(url):
# random.choice 从 user_agent 库中随机取出 user_agent 构建请求头
headers = {
'user-agent':random.choice(USER_AGENT_LIST)
}
# GET
resp = requests.get(url,headers=headers)
# 判断是否出现异常
resp.raise_for_status()
# 使用 lxml 解析器
soup = BeautifulSoup(resp.content, 'lxml')
return soup
# 爬取个人博客主页中博主的文章标题和文章链接
def get_url():
# 获取博客主页的网页内容
soup = get_response(my_website)
# 提取出网页中的文章列表内容
#class="article-list"
article_div = soup.find('div', attrs={'class': 'article-list'})
# 提取出所有文章的信息
articles_titles = article_div.find_all('h4')
# 从每一条文章信息里面提取出文章的标题和链接信息
articles = []
for article_title in articles_titles:
articles.append(article_title.find('a'))
# 建立文章链接的集合,输出文章的标题和链接
# 将每一篇文章的链接 url 加入文章链接集合中
urls = []
for article_url in articles:
print(article_url.text.strip())
urls.append(article_url.get("href"))
print('URL : ', article_url.get("href"), end = '\n\n')
#返回文章链接的集合
return urls
# 爬取个人博客主页中关于博主的个人信息
def get_Profile():
# 获取博客主页的网页内容
soup = get_response(my_website)
# 从网页内容中提取博主的个人简介信息
#id="asideProfile"
Profile = soup.find('div', attrs={'id': 'asideProfile'})
# 提取关于(原创,粉丝...)的信息
#class="data-info d-flex item-tiling"
item_tiling = Profile.find('div', attrs={'class': 'data-info d-flex item-tiling'})
# print(type(item_tiling))
# 输出提取到的博主个人信息
information = item_tiling.find_all('dl')
for inf in information:
# print(type(inf.text))
classification = inf.find('dd')
print(classification.text, end = " : ")
print(inf.get('title'))
# 访问每一篇文章,获取文章的信息
def get_visit(url):
# 获取文章的网页内容
soup = get_response(url)
# 提取文章的标题栏,得到文章的标题
#class="article-title-box"
article_title_box = soup.find('div', attrs={'class': 'article-title-box'})
print('成功访问 : ', article_title_box.text.strip())
# 提取文章的各种信息
#class="article-bar-top"
article_bar_top = soup.find('div', attrs={'class': 'article-bar-top'})
# 提取文章的访问数
# class="read-count"
read_count = article_bar_top.find('span', attrs={'class': 'read-count'})
print('访问:', read_count.text.strip(), end = '\t')
# 提取文章的收藏数目
# id="blog_detail_zk_collection"
collection = article_bar_top.find('a', attrs={'id': 'blog_detail_zk_collection'})
# class="get-collection"
collection_num = collection.find('span', attrs={'class': 'get-collection'})
# 使用正则表达式匹配收藏数的数值
number = re.sub('\D', '', collection_num.text)
print('收藏:', number, end='\n\n')
# main
if __name__ == '__main__':
# 文章链接的集合
all_urls = []
# 爬取个人博客主页中关于博主的个人信息
get_Profile()
# 爬取个人博客主页中所有文章的信息,得到每篇文章的链接 url
all_urls = get_url()
print('获取到的链接数:',len(all_urls))
# 查看爬取得到的文章链接 url
for url in all_urls:
print(url)
# 访问每一篇文章,获取文章的信息(合法刷访问量)
for loop in range(30):
# 从文章链接集合中取出一条文章链接 url
for url in all_urls:
try:
# 访问这篇文章
get_visit(url)
except Exception as e:
print(e)
continue
# 查看此时的博主个人博客信息
get_Profile()
# 等待一段时间
sleep_time = random.randint(65, 80)
print('等待', sleep_time, 's')
time.sleep(sleep_time)
执行结果展示
爬取个人博客主页中关于博主的个人信息 + 爬取个人博客主页中博主的文章标题和文章链接
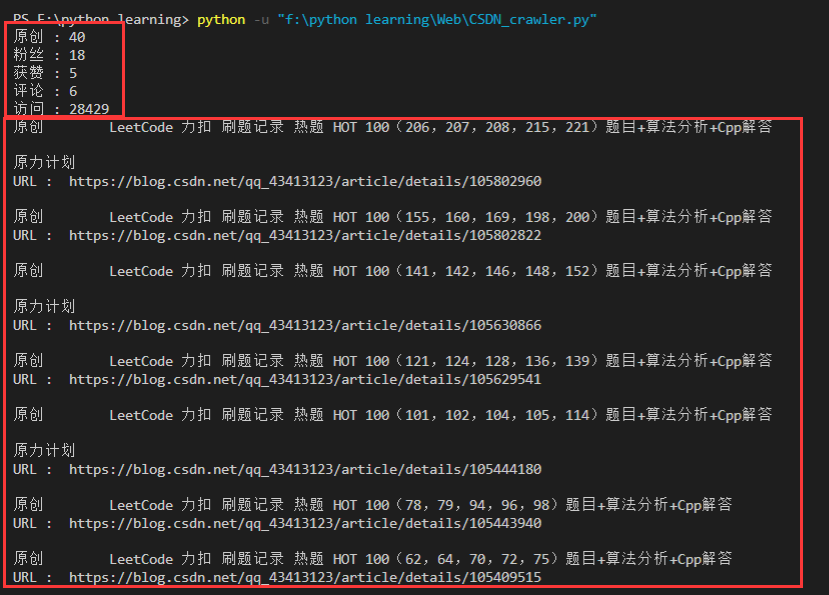
查看爬取得到的文章链接 url
访问每一篇文章,获取文章的信息